Método Floresta Aleatória (Random Forest)




A floresta aleatória, também conhecida como random forest, é um método de aprendizagem de máquina que pode ser usado para classificar e regredir variáveis binárias ou contínuas. Este método é baseado em construir vários modelos de árvores de decisão, a partir de diferentes subconjuntos dos dados de treinamento e, em seguida, combinar os resultados destes modelos para melhorar as estatísticas de precisão dos resultados.
Uma vez que as árvores de decisão são criadas, elas são usadas para fazer previsões sobre novas amostras de dados. As previsões das diferentes árvores são então combinadas para produzir uma previsão final mais precisa. Existem várias maneiras de combinar as previsões das árvores, mas a mais comum é simplesmente calcular a média delas a fim de chegar a uma predição final da floresta aleatória, gerando o resultado da variável de interesse.
Vantagem
A principal vantagem da floresta aleatória, é que ela tem alto grau de precisão (acertos), mesmo com dados complexos e não linearmente separáveis. Além disso, esse método é menos suscetível a overfitting do que outros métodos de aprendizagem de máquina, como a regressão logística.
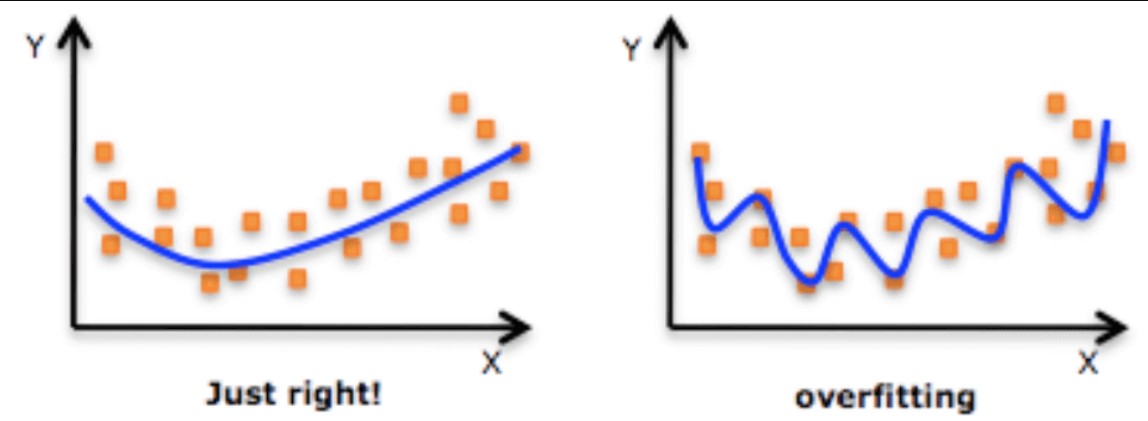
O que é overfitting?
É quando o modelo trabalha muito a base treino e, por consequência, , mostra-se adequado apenas para os dados de treino, como se o modelo tivesse somente decorado os dados de treino e não fosse capaz de generalizar para outros dados nunca vistos antes. Quando isso acontece, os dados de treino apresentam resultados excelentes e quando aplicado a base teste, sua performance cai drasticamente.
Desvantagens
A floresta aleatória tem algumas desvantagens. Em primeiro lugar, esse método requer mais tempo para treinar o modelo do que outros métodos, pois é necessário construir várias árvores. Além disso, esse método pode ser menos eficiente do que outros métodos em termos de uso de memória do dispositivo, uma vez que cada árvore na floresta precisa ser armazenada individualmente na memória.
A construção do algoritmo da floresta aleatória consiste em três etapas principais:
Gerenciar o conjunto de dados para cada árvore na floresta.
Construir cada árvore usando um subconjunto aleatório dos dados.
Combinar as previsões das árvores para produzir uma previsão final mais precisa.
Os parâmetros da floresta aleatória podem ser ajustados para melhorar a precisão do modelo. Um parâmetro importante é o número de árvores na floresta, que determina quantos subconjuntos dos dados de treinamento serão usados para construir as árvores. Quanto maior o número de árvores, melhor será a precisão do modelo, mas também levará mais tempo para treinar o modelo. Outro parâmetro importante é o tamanho do subconjunto dos dados de treinamento usado para construir cada árvore. Quanto maior for este tamanho, melhor será a precisão do modelo, mas também levará mais tempo para treinar o modelo.